MuSE-SVS
Multi Singer Emotional Singing Voice Synthesizer that Controls Emotional Intensity
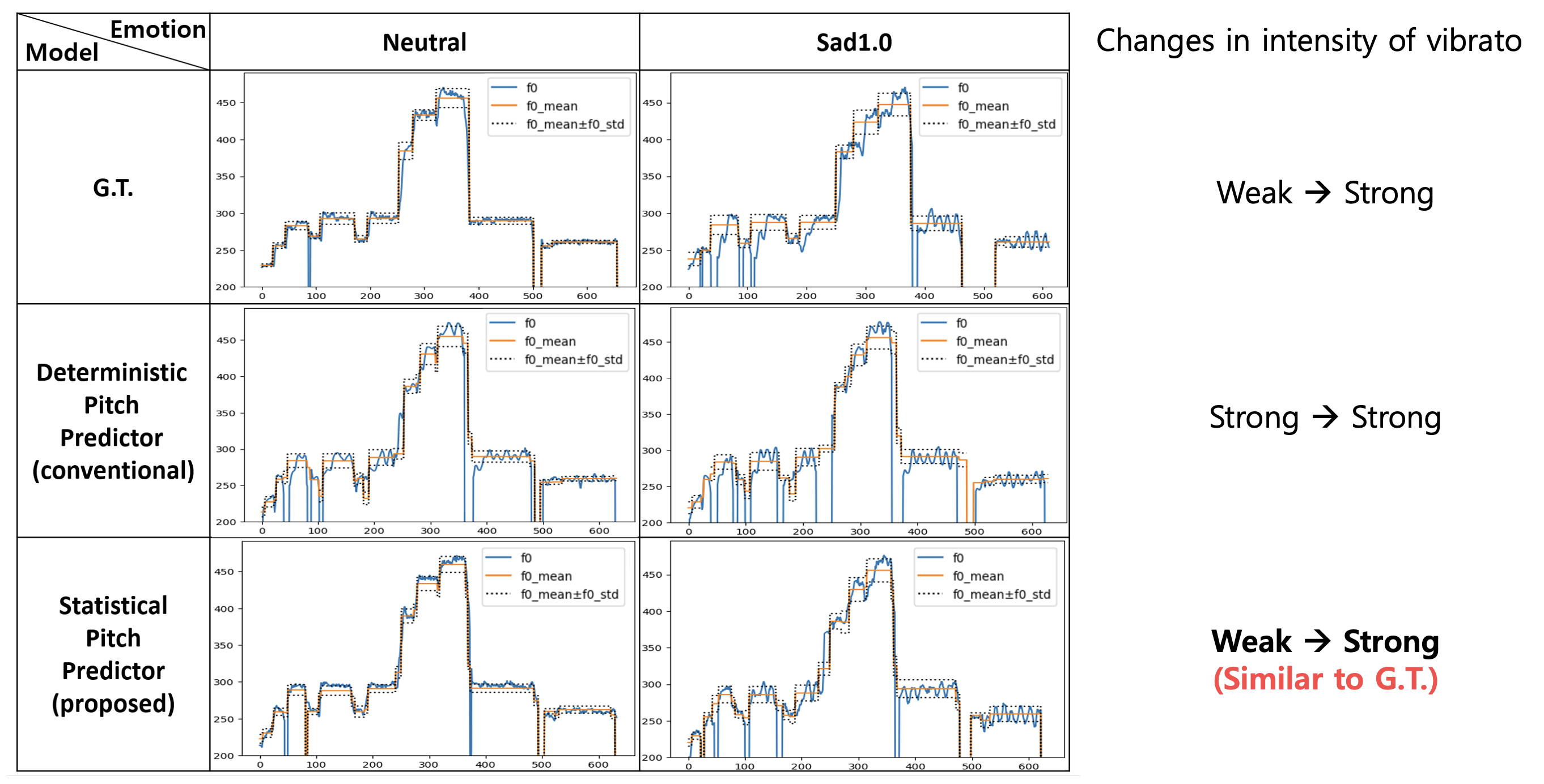
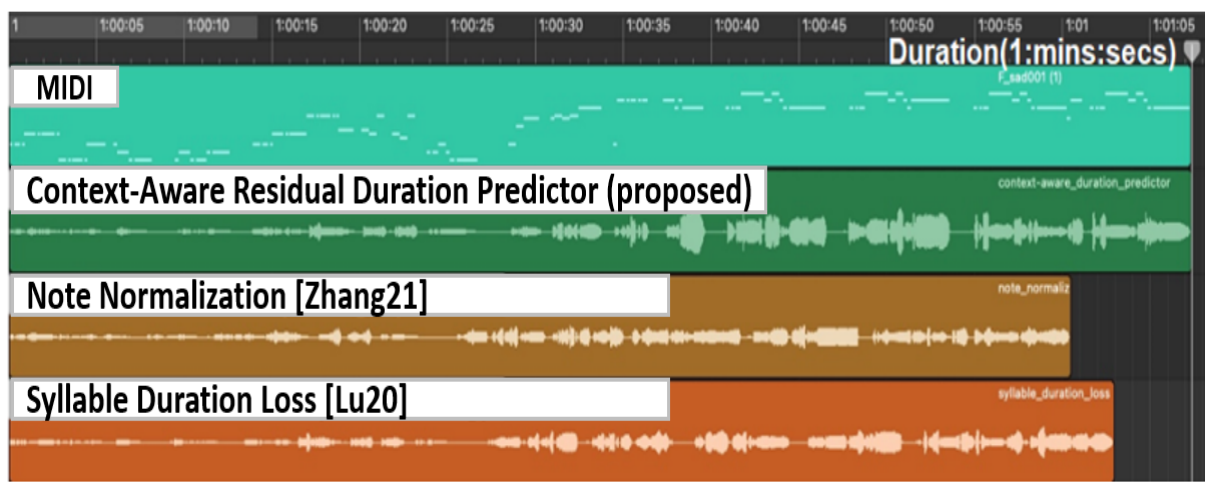
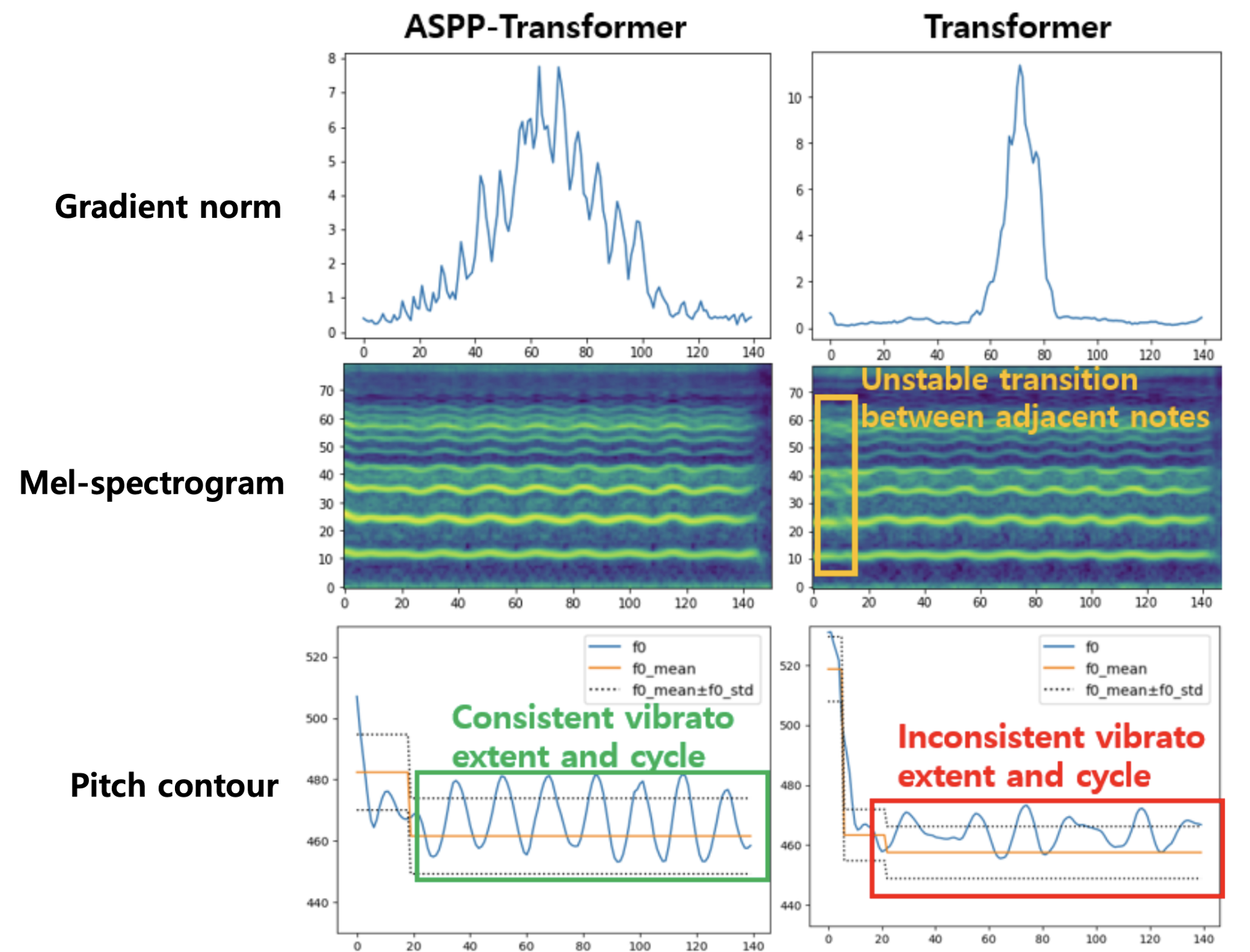
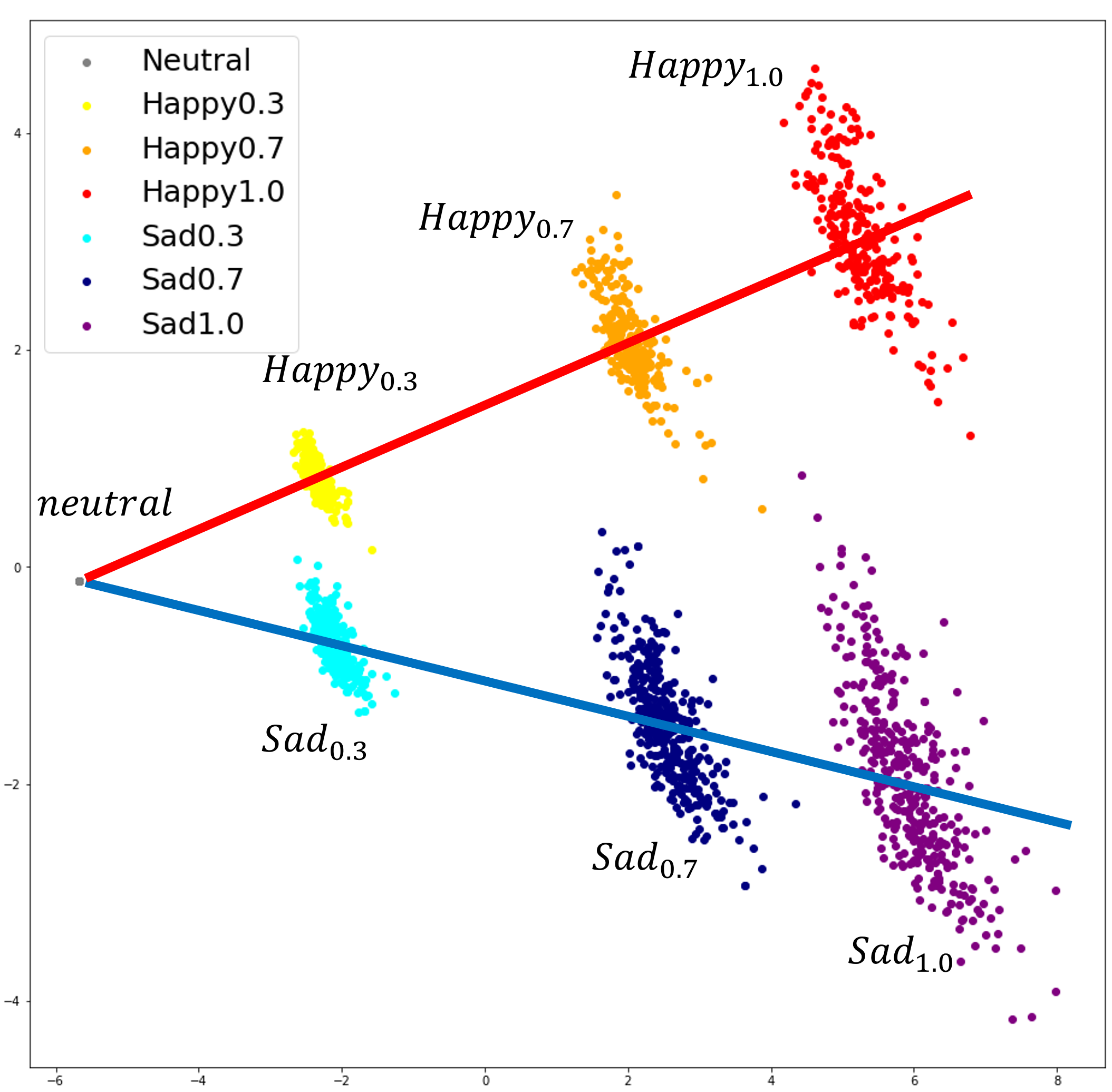
We propose a multi-singer emotional singing voice synthesizer, Muse-SVS, that expresses emotion at various intensity levels by controlling subtle changes in pitch, energy, and phoneme duration while accurately following the score. To control multiple style attributes while avoiding loss of fidelity and expressiveness due to interference between attributes, Muse-SVS represents all attributes and their relations together by a joint embedding in a unified embedding space. Muse-SVS can express emotional intensity levels not included in the training data, including even stronger emotions than those in the training data through embedding interpolation and extrapolation. We also propose a statistical pitch predictor to express pitch variance according to emotional intensity, and a context-aware residual duration predictor to prevent the accumulation of variances in phoneme duration, which is crucial for synchronization with instrumental parts. In addition, we propose a novel ASPP-Transformer, which combines atrous spatial pyramid pooling(ASPP) and Transformer, to improve fidelity and expressiveness by referring to broad contexts. In experiments, Muse-SVS exhibited improved fidelity, expressiveness, and synchronization performance compared with the baseline models. The visualization results show that Muse-SVS effectively express the variance in pitch,energy, and phoneme duration according to emotional intensity. To the best of our knowledge, Muse-SVS is the first neural SVS capable of controlling emotional intensity.
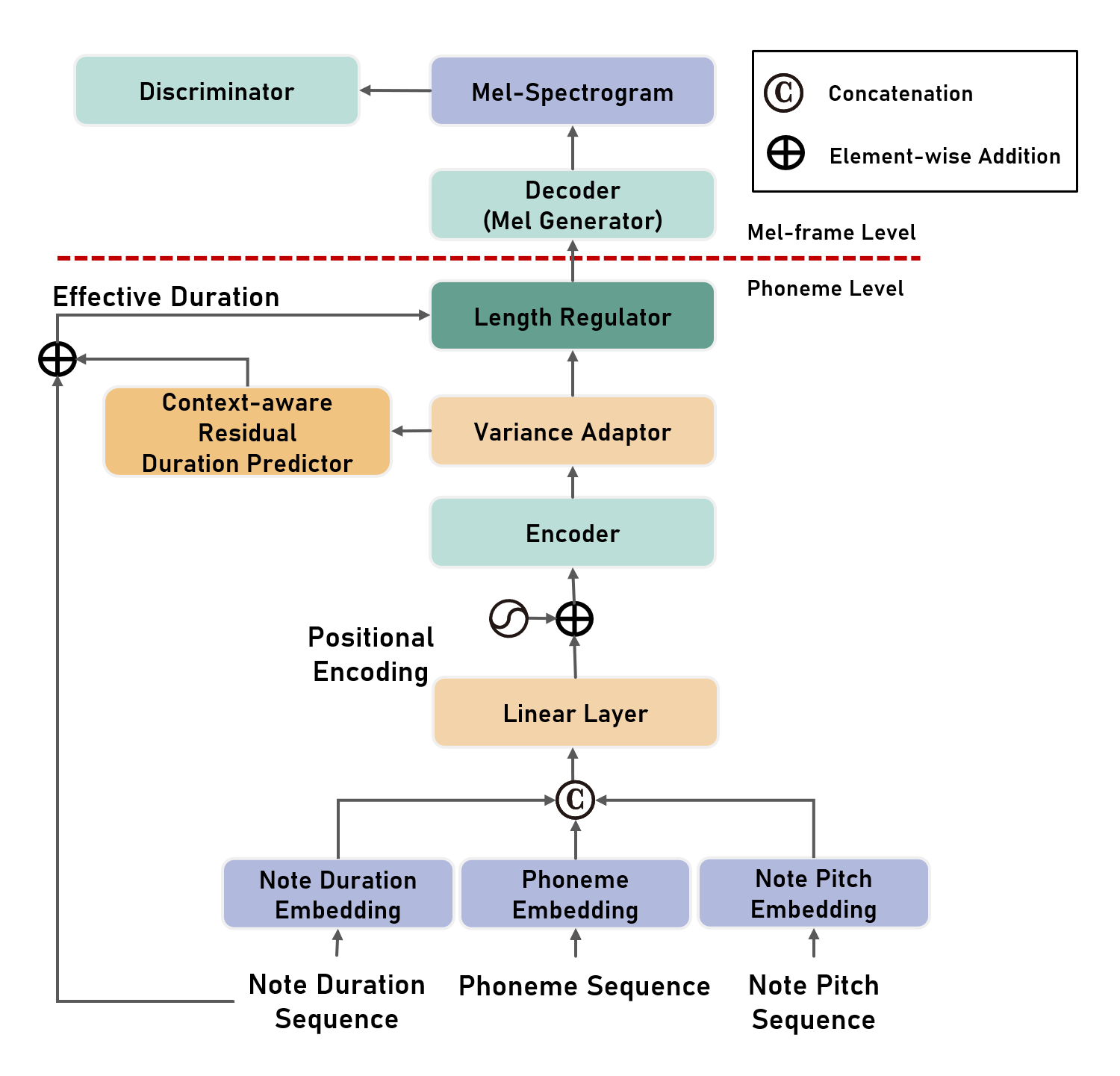 | 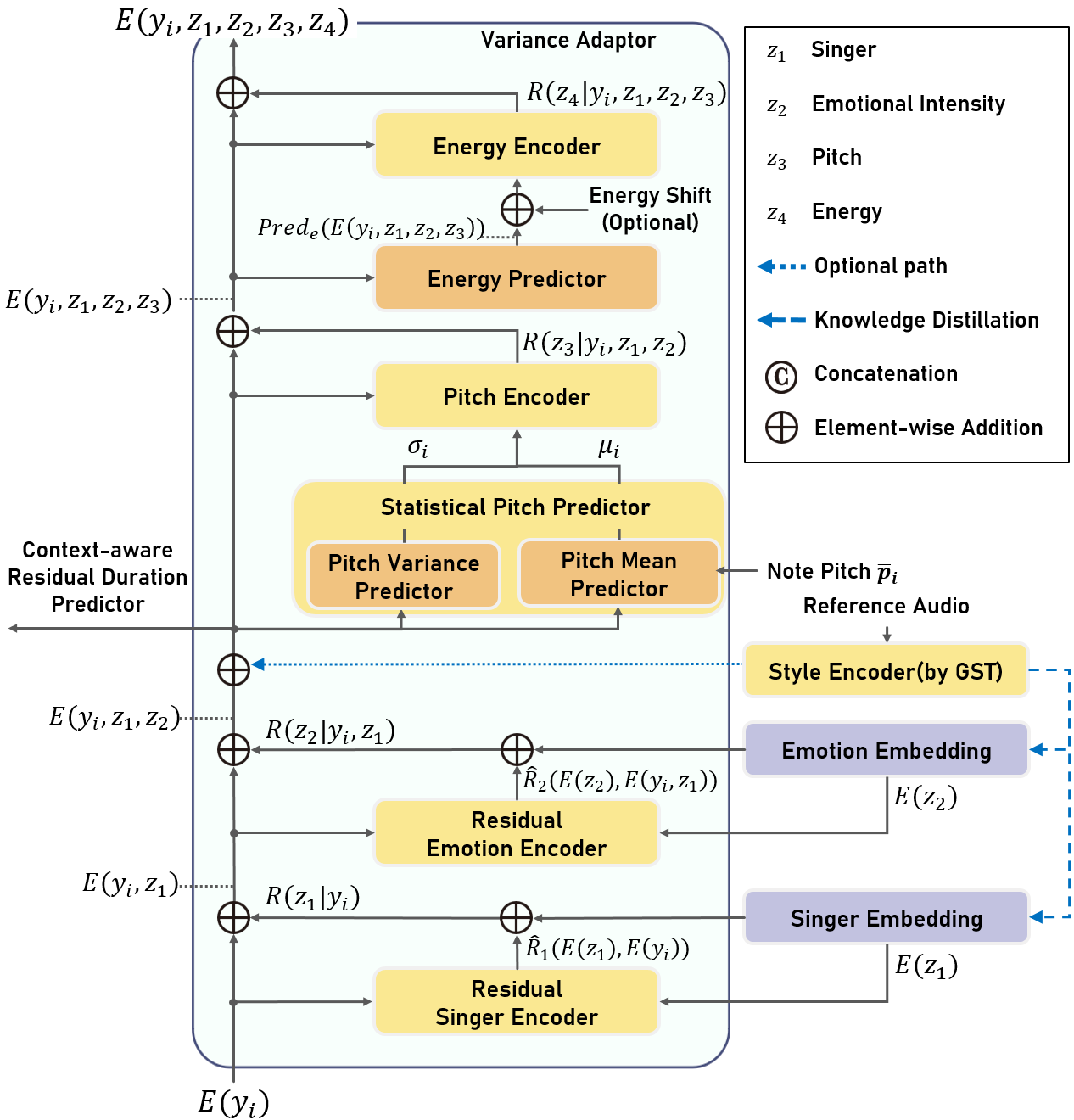 |
| Model Overall Structure | Variance Adaptor Structure |
Audio Demo
Demonstaration of overall performancePlease listen to the samples, focusing on expressiveness and fidelity.
(There are the samples of other intensity levels in here)
Samples of female singer (Happy)
Neutral Happy 1.0 MuSE-SVS
(proposed)MSME-VISinger VISinger Demo MSME-FFTSinger GT
Samples of male singer (Sad)Neutral Sad 1.0 MuSE-SVS
(proposed)MSME-VISinger VISinger Demo MSME-FFTSinger GT